
- JPQL에서 성능 최적화를 위해 제공하는 기능이다.
- 연관된 엔티티나 컬렉션을 한 번의 SQL로 모두 조회하는 기능이다.
join fetch를 이용한다.
// jpql
select m from Member m join fetch m.team
// SQL
select m.*, T.* from Member m
inner join team t on m.team_id = t.id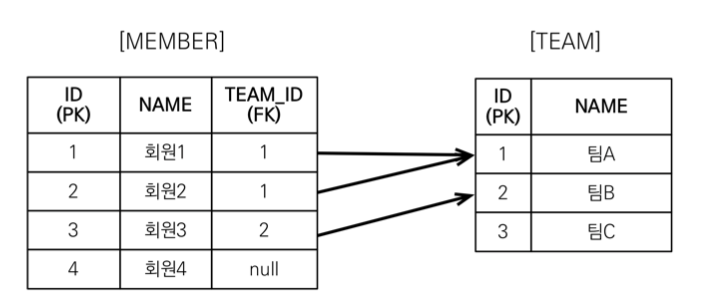
List<Member> resultList = em.createQuery("select m from Member m", Member.class).getResultList();
for (Member member1 : resultList) {
System.out.println("member1.getUsername() = " + member1.getUsername() + " , teamName = " + member1.getTeam().getName() );
}
- LAZY로 잡힌 연관관계 엔티티는 프록시로 가져오고 조회 시점에 지연 로딩하여 쿼리를 날린다.
- 회원 조회 쿼리 1번(4개의 Row를 가져온다.) + 회원에 속한 팀 조회 쿼리 N번(최대 4번 발생) → N + 1 문제 발생
- N + 1 문제를 해결하기 위해 fetch join을 이용하자!
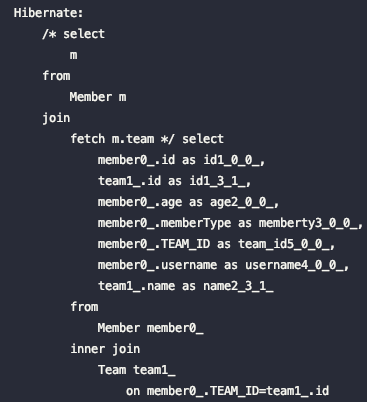
List<Member> resultList = em.createQuery("select m from Member m join fetch m.team", Member.class).getResultList();
for (Member member1 : resultList) {
// 조회 시점에 Member, Team을 모두 영속성 컨텍스트에 가져왔기 때문에 프록시가 아니다.
// getTeam.getName()을 하는 시점에 쿼리가 발생하지 않는다. (지연로딩되지 않는다.)
System.out.println("member1.getUsername() = " + member1.getUsername() + " , teamName = " + member1.getTeam().getName() );
}
- 1:N 조인의 경우 데이터가 늘어난다.
- 컬렉션 페치조인의 경우 동일한 값을 가지면 하나의 영속성 컨텍스트 주소를 갖는다.


- JPQL은 Distinct를 이용해 중복을 제거하는 것이 가능하다.
- 발생하는 SQL 쿼리에 Distinct를 추가해준다.
- 애플리케이션에서 엔티티 중복을 제거해준다.
- 위에서 Team (id = 1, name = 팀A) 엔티티가 중복이기 때문에 JPA가 중복을 제거해준다. (Distinct 2번 기능)
select distinct t from Team t join fetch t.members
페치 조인 vs 일반 조인
- 일반 조인을 실행하면 연관된 엔티티를 같이 조회하지 않기 실제 조회 시점에 지연 로딩한다.
- fetch join은 연관된 엔티티를 같이 조회하기 때문에 실제 조회 시점에도 지연 로딩이 발생하지 않는다. 즉, 연관된 엔티티만 즉시 로딩한다.
- 페치 조인은 객체 그래프를 SQL 한 번으로 조회하는 것이다.
페치 조인 특징 및 한계
- 객체 그래프 탐색의 기본적인 정의는 연관된 엔티티의 데이터를 모두 탐색하는 것이다.
- 페치 조인은 연관된 엔티티를 모두 가져오는 것이기 때문에 페치 조인하는 대상에 별칭을 주지 않는다.
- 별칭을 주고 where절에 조건을 걸어 데이터를 조회한다면 전체 엔티티를 불러오고자 페치 조인을 사용했지만, 조건에 따라 데이터가 걸러져 전체 엔티티를 못 불러오는 경우가 생길 수 있기 때문이다.
- 조건을 걸어 조회를 하고 싶은 경우 조회 자체 대상을 페치 조인 대상으로 조회하자.
- A → B → C 순으로 연관관계가 있는 경우에 B 엔티티에는 별칭을 줘서 C를 페치 조인으로 가져오는 건 사용한 적이 있다. (김영한 강사님 피셜..)
// Team의 연관관계 member는 5개의 데이터를 가지고 있지만 m.age로 인해 데이터가 줄어든다.
"select t from Team t join t.members m where m.age > 10"
- 둘 이상의 컬렉션은 페치 조인할 수 없다.
- 1 : N : M → 1 * N * M 개의 데이터가 나올 수 있기 때문에 데이터 정합성 면에서 문제가 생길 수 있다.
- 컬렉션을 페치 조인하면 페이징 API를 사용할 수 없다.
- XtoMany의 관계는 데이터가 늘어난 상태로 DB를 조회한다.
- XtoOne의 관계의 경우 페치 조인을 사용해도 데이터가 늘어나지 않은 상태이기 때문에 페이징이 가능하다.
- 하이버네이트는 경고 로그를 남기고 메모리에서 페이징을 한다. → 메모리에서 사용하기 때문에 예기치 못한 에러 발생 가능
- 해결 방법
- 양방향 연관 관계인 경우 XtoMany 탐색이 아닌 xToOne으로 탐색을 하면 페이징 처리를 할 수 있다.
- 페치 조인 없이 엔티티를 조회하고 (쿼리 한번 1번 → 컬렉션 데이터 (3개 가정) )) 조회한 컬렉션 엔티티를 루프를 돌면서 조회한다. (쿼리 3번 발생) → 성능적인 측면에서 좋지 않다. (N + 1 문제 발생)
- ✨ @BatchSize를 이용한다. 지정한 사이즈만큼 IN절에 PK를 넣어 데이터를 가져온다.
@BatchSize(size = 100)
@OneToMany(mappedBy = "team")
private List<Member> members = new ArrayList<>();
List<Team> resultList = em.createQuery("select t from Team t", Team.class)
.setFirstResult(0)
.setMaxResults(2)
.getResultList();
- 지연 로딩보다 페치 조인이 우선순위가 높다.
- 최적화가 필요한 부분은 페치 조인을 이용한다.
- 여러 테이블을 조인해서 엔티티와 다른 모양의 데이터 결과를 받는 경우 일반 조인을 사용하고 DTO로 반환받는다.
📄 References
김영한님의 자바 ORM 표준 JPA 프로그래밍 - 기본편 : https://www.inflearn.com/course/ORM-JPA-Basic/dashboard
반응형
'Backend > JPA' 카테고리의 다른 글
| Spring Data Jpa (0) | 2022.08.22 |
|---|---|
| JPQL 중급 (0) | 2022.08.03 |
| JPQL 기본 (0) | 2022.07.29 |
| 값 타입 (0) | 2022.07.26 |
| 영속성 전이 (Cascade), 고아 객체 (0) | 2022.07.21 |