
Confluent Kafka Course 읽고 정리하기
카프카는 데이터와 메타데이터를 분리해서 다룬다.
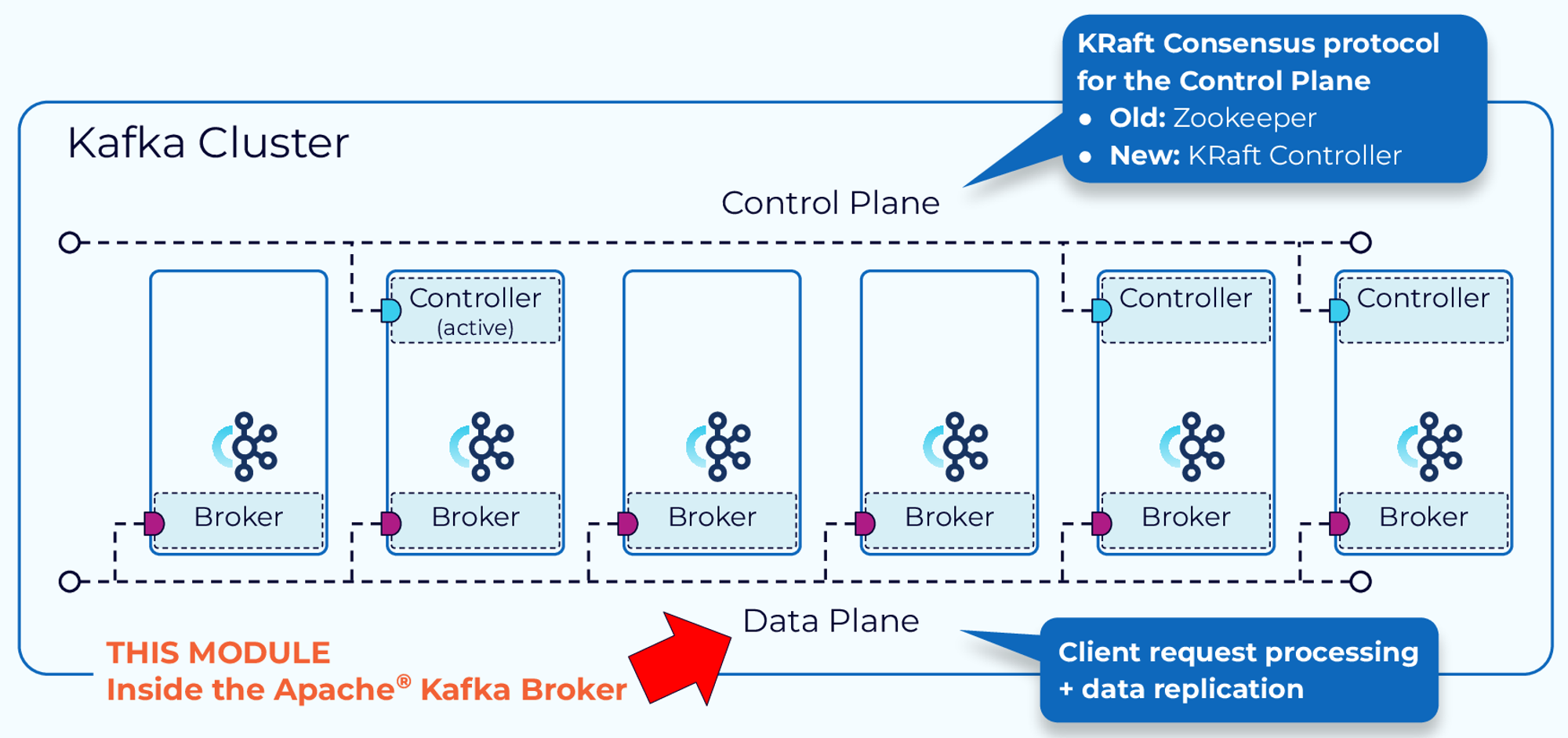
- 카프카 클러스터 내 기능은 Data Plane과 Control Plane으로 나뉜다.
- Control Plane: 카프카 클러스터의 메타데이터 관리를 처리한다.
- Data Plane: 카프카에서 읽고 쓰는 전체 데이터를 다룬다.
카프카 브로커 내부 구조

- 카프카에서 클라이언트 요청은 Produce, Fetch request 두 분류로 나뉜다.
- Produce Request: 데이터 배치를 특정 토픽에 쓰도록 요청
- Fetch Request: 카프카 토픽에서 데이터를 가져오는 요청
- 두 요청 모두 동일한 단계를 거친다.
Producer Request
파티션 할당

- 프로듀서가 레코드를 전송할 준비가 되면, 파티셔너를 이용해 레코드에 할당할 토픽 파티션을 결정한다.
- 레코드에 키가 있는 경우 Default Partitioner로 키의 해시를 사용한다.
- 동일한 키를 갖는 레코드는 동일한 파티션에 할당된다.
- 레코드에 키가 없는 경우 파티션에 레코드를 균등하게 할당한다. (Round Robin)
레코드 배치

- 프로듀서는 파티션에 할당된 레코드를 누적시킨 뒤 배치로 전송해서 네트워크 요청으로 인한 오버헤드를 줄인다.
- 레코드 누적을 통한 배치 처리는 압축에 있어서도 효율이 좋다.

- 프로듀서는 linger.ms, batch.size 속성을 이용해 레코드 배치를 언제 브로커로 전송할지 제어할 수 있다.
- linger.ms(시간): 프로듀서가 레코드를 배치로 보내기 위해 최대로 대기하는 시간
- batch.size(크기): 프로듀서가 하나의 배치로 보낼 수 있는 최대 크기
- 레코드 배치에 충분한 시간(linger.ms)이 지나거나 충분한 데이터(batch.size)가 누적되면, 레코드 배치는 삭제되고 produce request가 생성된다.
- 생성된 produce request는 해당 파티션의 리더 브로커로 전송된다.
네트워크 스레드가 큐에 요청을 추가한다.

- produce request는 가장 먼저 브로커의 socket receive buffer에 적재되고, 네트워크 풀에 있는 네트워크 스레드에 의해 처리된다.
- 요청을 가져간 네트워크 스레드는 해당 요청을 라이프 사이클동안 자신이 모두 관리한다.
- 네트워크 스레드는 데이터를 소켓 버퍼로부터 읽고, producer request object로 만들며, 이를 request queue에 추가한다.
I/O 스레드가 배치를 검증하고 저장한다.

- I/O 스레드 풀의 스레드는 큐에서 요청을 꺼낸 후 요청 내 데이터에 대한 검증(데이터의 CRC Check)등을 수행한다.
- I/O 스레드는 commit log라고도 불리는 물리적 데이터 구조인 파티션에 데이터를 추가한다.
Kafka의 물리적 저장소

- 디스크 내에 commit log는 세그먼트라는 컬렉션으로 구성된다.
- 각 세그먼트는 여러 개의 파일로 구성된다.
- .log
- 카프카 토픽에 저장된 실제 이벤트 데이터의 특정 오프셋까지 저장되어 있는 파일
- 파일명은 해당 로그의 시작 오프셋 값을 의미한다.
- .index
- 레코드 오프셋과 .log 파일의 해당 레코드의 위치와 매핑되는 인덱스 정보를 저장하는 파일
- .index 에 저장된 인덱스를 이용해 전체 .log 파일 스캔 없이 로그에 지정된 오프셋의 레코드를 액세스할 수 있다.
- .timeindex: 로그의 타임스탬프를 기준으로 레코드에 액세스하는데 사용되는 인덱스를 저장하는 파일
- .snapshot
- 중복 레코드를 전송하는 것을 피하기 위해 사용되는 시퀀스 ID에 관련된 프로듀서의 상태의 스냅샷을 저장하는 파일
- 새로운 리더가 선출되고, 선호되던 기존 리더가 살아나서 다시 리더가 되기 위해 해당 스냅샷 정보를 읽는다.
- .log
Purgatory는 다른 브로커에도 요청이 복제될 때까지 요청을 홀딩한다.

- 페이지 캐시에 저장된 로그 데이터는 디스크에 동기적으로 전달되는 것이 아니기 때문에 카프카는 내구성을 보장하기 위해 다른 브로커에 복제한다.
- 다른 브로커에 복제되기 전까지 요청에 대한 응답을 반환하지 않는다.
- 다른 브로커에 복제될 때까지 I/O 스레드가 대기하는 것은 비효율적이기 때문에 Purgatory라는 Map 형태를 갖는 저장소에 request object가 저장된다.
- 다른 브로커에 복제가 완료되면, Purgatory 에서 해당 요청을 꺼내고 response object를 만들어 response queue에 저장한다.
응답을 소켓에 추가한다.

- 네트워크 스레드는 response queue로부터 생성된 response object를 꺼내서 Socket Send Buffer에 저장한다.
- 네트워크 스레드는 현재 처리 중인 클라이언트의 응답이 전송될 때까지 모든 바이트를 기다렸다가 response queue에서 다른 객체를 가져간다.
네트워크 스레드의 특징
- 클라이언트가 브로커에 연결을 요청하면, 네트워크 스레드 풀에 존재하는 스레드 중 하나의 스레드와 커넥션을 맺는다.
- 클라이언트는 하나의 네트워크 스레드와 연결을 맺지만, 네트워크 스레드는 여러 클라이언트와 연결을 맺는 1:N 관계이다.
- 네트워크 스레드는 연결을 맺은 클라이언트의 요청부터 응답까지의 라이프 사이클을 관리한다.
- 네트워크 스레드는 각각의 Response Queue를 갖는다.
- 특정 클라이언트에 대한 요청을 특정 네트워크 스레드가 처리하기 때문에 특정 클라이언트의 요청 순서는 네트워크 스레드가 보장한다.
Fetch Request

- 컨슈머 클라이언트는 토픽, 파티션, 오프셋 정보를 지정해 브로커에 Fetch Request를 보낸다.
- Produce Request와 동일하게 전달된 Fetch Request는 소켓 버퍼에 저장되고, 네트워크 스레드가 이를 Request Queue에 저장한다.
- I/O 스레드는 Request Queue에서 가져온 오프셋과 파티션 세그먼트에 저장된 .index 파일의 오프셋과 비교한다.
- 오프셋과 매핑된 .log 레코드 위치를 알 수 있으므로 읽을 바이트 범위를 정확하게 판단할 수 있다.
- 매 레코드마다 요청과 응답을 반복하는 것은 비효율적이다.
- 응답하기 까지의 최대 대기 시간 혹은 최소 사이즈가 충족될 때까지 요청을 홀딩하고 충족되는 요청에 대한 응답을 모아서 전송한다.
- 최대 대기 시간, 최소 사이즈가 충족될 때까지 Purgatory에 Fetch Request를 저장한다.
최대 대기 시간, 최소 사이즈를 구성하는 Consumer Configuration
- fetch.max.wait.ms: Fetch Request를 응답하기 전까지 최대로 대기할 수 있는 시간 (default: 500ms)
- fetch.min.bytes: Fetch Request를 응답하기 위한 최소 데이터 양 (defalut: 1)
- 설정으로 구성한 최대 대기 시간, 최소 사이즈가 충족되면 Purgatory에서 Fetch Request를 빼서 Response Queue에 저장한다.
- 네트워크 스레드는 Response Queue에서 응답을 가져와서 소켓 버퍼에 저장하고 컨슈머 클라이언트에게 전송한다.
Reference.
Confluent: Inside the Apache Kafka Broker
LINE에서 Kafka를 사용하는 방법 - 2편
반응형
'Kafka > Kafka' 카테고리의 다른 글
| Kafka: Exactly-Once Semantic (w/ Transaction_) (0) | 2025.01.27 |
|---|---|
| Kafka Connect: Incremental Cooperative Rebalancing (0) | 2024.12.09 |
| Kafka: Static Membership (0) | 2024.11.03 |
| Kafka Issue: InvalidRecordException (related Timestamp) (0) | 2024.06.01 |